
Active Learning
Active Learning : 모델이 어려워하는 데이터를 판별하여, 판별된 데이터를 유저가 효율적으로 학습할 수 있도록 도와주는 기법
Active Learning이란 기초적인 AI모델이 자신의 학습에 필요한 Data를 요구하여 요구한 Data에 Annotator가 Labeling을 해주는 학습 방식을 말한다.
자세히 알아보면 여기서 말하는 기초적인 AI모델은 적은 데이터로 학습한 AI모델을 뜻한다. 적은데이터로 학습했으니 부족한 정보가 있을것이다. 이 부족한 정보를 채워주기 위해 어느 정보가 부족한지 라벨링되지 않은 새로운 데이터셋으로 Inference해본다. Inference 후 정보가 부족하다는 데이터에 추가적인 Labeling을 해주면 부족한 정보가 조금 완화된 AI 모델을 얻을수 있을것이다.
Active Learning을 정리해보면 아래의 그림과 같다.
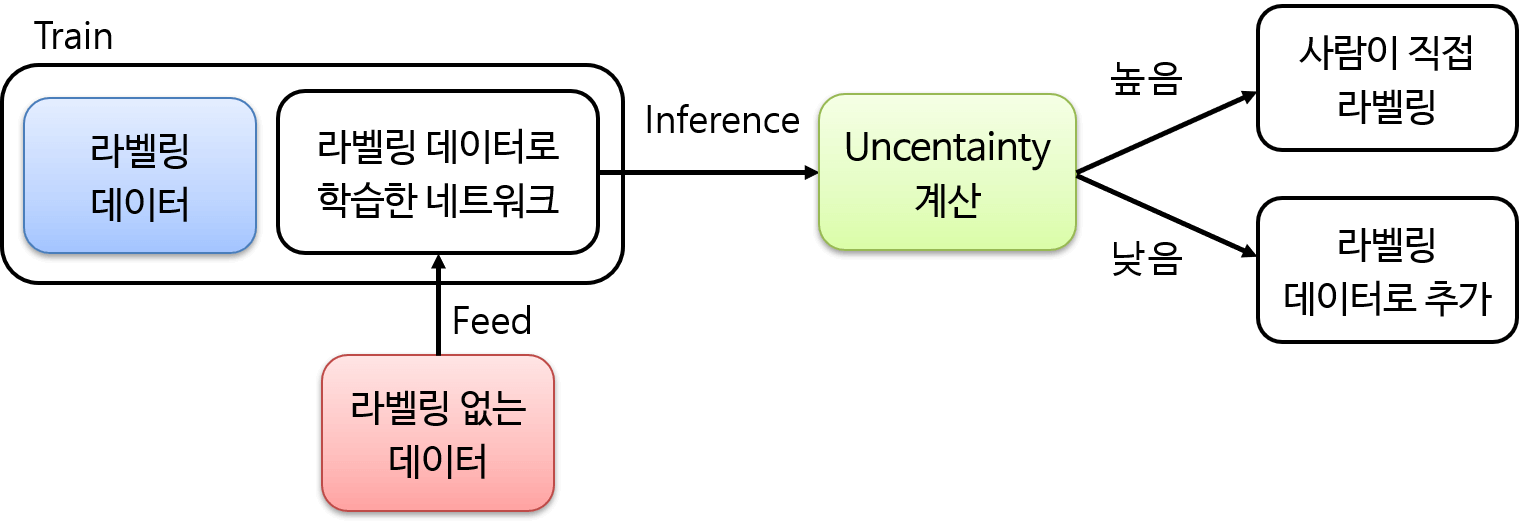
정보가 부족하다는 것은 쿼리를 통해 전달하게된다.
기본적으로 불확실성의 척도를 가지고 쿼리를 보내게되고 Least Confident, Margin Sampling, Entropy Sampling 3가지 전략이 주로 사용된다.
Least Confident
- 모델이 예측한 Top1 확률이 가장 낮은 데이터부터 쿼리를 보냄
| 데이터 | Class 1 | Class2 | Class3 | Top1 | Query Priority |
|---|---|---|---|---|---|
| d1 | 0.1 | 0.2 | 0.7 | 0.7 | 4 |
| d2 | 0.33 | 0.33 | 0.34 | 0.34 | 1 |
| d3 | 0.3 | 0.4 | 0.3 | 0.4 | 2 |
| d4 | 0.41 | 0.39 | 0.2 | 0.41 | 3 |
Margin Sampling
- 모델이 예측한 Top1, Top2 확률 차이가 가장 낮은 데이터부터 쿼리를 보냄
| 데이터 | Class 1 | Class2 | Class3 | Top1 - Top2 | Query Priority |
|---|---|---|---|---|---|
| d1 | 0.1 | 0.2 | 0.7 | 0.5 | 4 |
| d2 | 0.33 | 0.33 | 0.34 | 0.01 | 1 |
| d3 | 0.3 | 0.4 | 0.3 | 0.1 | 3 |
| d4 | 0.41 | 0.39 | 0.2 | 0.02 | 2 |
Entropy Sampling
- 모델이 예측한 엔트로피가 가장 큰 데이터부터 쿼리를 보냄
| 데이터 | Class 1 | Class2 | Class3 | Entropy | Query Priority |
|---|---|---|---|---|---|
| d1 | 0.1 | 0.2 | 0.7 | 0.3482 | 4 |
| d2 | 0.33 | 0.33 | 0.34 | 0.4771 | 1 |
| d3 | 0.3 | 0.4 | 0.3 | 0.4729 | 2 |
| d4 | 0.41 | 0.39 | 0.2 | 0.4580 | 3 |
위에서 확인한것과 같이 Sampling 방식에 따라 Query Priority의 변동이 생긴다.
또한 Sampling 방식에 따라 불확실성의 변동을 Heatmap으로 그려보면 다음과 같으며, 이를 고려하여 상황에 맞게 적용하면 될것같다. (그림에서 코너는 한 클래스가 높은 확률을 갖는 곳이다. )
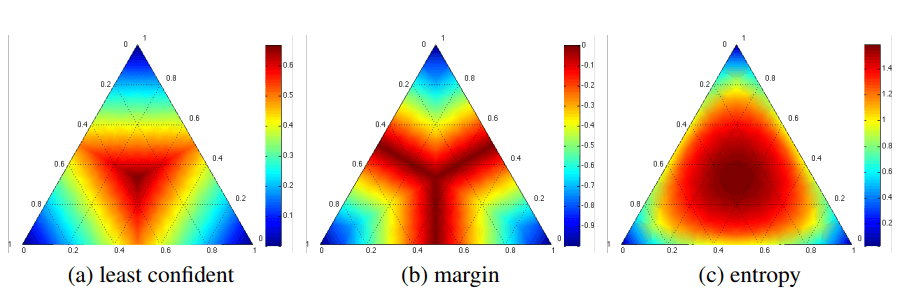
또한 이외에도 Query-By-Committee / Expected Model Change / Core-Set / Learning Loss 등이 있지만 Learning Loss 가 비교적 최근이며 성능도 좋은것으로 알고있다.
Learning Loss ( https://arxiv.org/pdf/1905.03677.pdf )